
How to build Your First Machine Learning Model in Python
- Gowtham V
- Dec 14, 2024
- 4 min read

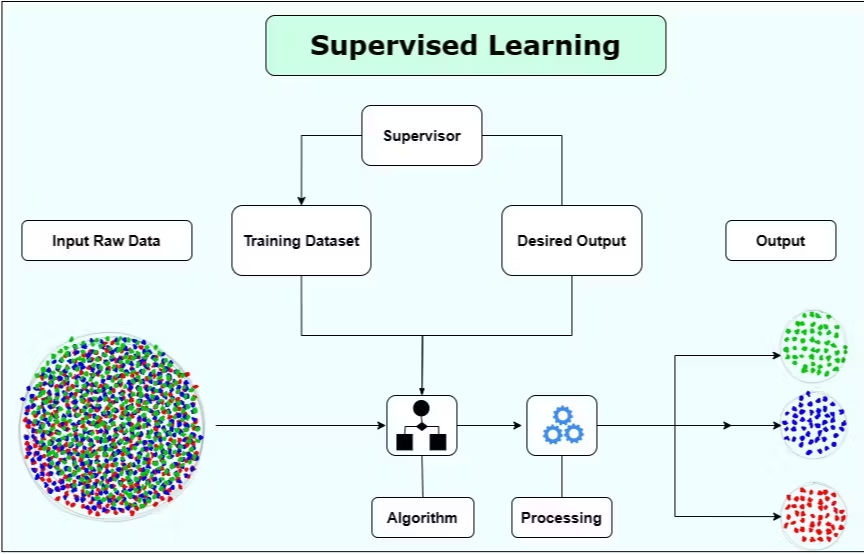
Machine Learning is a transformative technology that enables computers to learn from data and make predictions. If you're just starting in this field, building your first machine learning model in Python is a great way to gain hands on experience. In this beginner-friendly guide, we'll walk through the steps to build a simple model to predict flower variety, using Python and essential libraries like Pandas, NumPy and Scikit-Learn.
Why Python for Machine Learning?
Python is the go-to language for machine learning because of its simplicity and the powerful libraries that make data manipulation and modeling easy. Libraries like Scikit-Learn provide pre-built functions to handle data, split datasets and train models with just a few lines of code.
Step:1 Setup Your Environment
To get started, make sure you have Python installed. We'll be using Google Collab for this tutorial, as it allows for easy code testing and visualization.
Install Necessary Libraries
If you don't have them installed, you can use the following commands.
Code snippet:
pip install pandas numpy scikit-learnStep 2: Import Libraries and Load the Data
Let's start by importing the necessary libraries and loading a simpler dataset. In this example, we'll use Scikit-Learn's Iris Flower Dataset to predict flower variety based on features like the Sepal Length, Sepal Width, Petal Length and Petal Width.
Code Snippet:
# Importing the necessary libraries
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error# Loading the Iris Flower Dataset
iris = load_iris()
data = pd.DataFrame(iris.data, columns=iris.feature_names)
# Setting the 'variety' column as target variable
data['variety'] = iris.targetThe Iris Flower Dataset contains information about various features of flowers in the Iris family, like Sepal Length, Sepal Width, Petal Length and Petal Width. Our goal is to build a model that can predict the variety of the flower based on these features.
Step 3: Explore and Prepare the Data:
Before building the model, it's essential to understand the data. Let's check for missing values and basic statistics to get a sense of the dataset.
Code Snippet:
# Check for missing values
print(data.isnull().sum())
# Display basic statistics
print(data.describe())Feature Selection:
Selecting relevant features is a key to build an effective model. For this dataset, we'll use the following features: Sepal Length, Sepal Width, Petal Length and Petal Width.
Code Snippet:
# Feature Selection
x=data[['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']]
y=data['variety']Step 4: Split the Data into Training and Testing Sets
To evaluate our model's performance, we'll split the data into a training and testing sets. The training set is used to train the model, while the testing set evaluates its performance.
Code Snippet:
# Spliting the datasets into training(80%) and testing(20%) sets
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=42)Step 5: Choose a Machine Learning Model
For this example, we'll use Linear Regression. This algorithm is commonly used for regression problems and tries to find a relationship between the features and the target variable by fitting a straight line.
Code Snippet:
# Initialize the model
model = LinearRegression()Step 6: Train the model
Training the model involves feeding the training data to it so it can learn the relationships between the features and the target variable.
Code Snippet:
# Train the model
model.fit(x_train, y_train)Step 7: Make Predictions
Once the model is trained, use it to make predictions on the test data.
Code Snippet:
# Make predictions on the test data
y_pred = model.predict(x_test)Step 8 : Evaluate the Model
Model evaluation is a crucial step to understand how well the model performs. One common evaluation metric for Linear Regression is Mean Squared Error (MSE), which measures the average squared difference between predicted and actual values.
Code Snippet:
# Calculate the mean squared error
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error: ",mse)The lower the MSE value, the better the model's performance. You can experiment with different features or algorithms to try and reduce the MSE further.
Step 9: Interpret the results:
For a beginner, it's essential to understand what the model is doing. Here's how you can interpret the results:
Coefficients: The coefficients of the linear regression model indicate the weight each feature has on the prediction.
Code Snippet:
# Print model coefficients and model intercept
print("Model Coefficients: ", model.coef_)
print("Model Intercept: ",model.intercept_)Prediction vs Actual Values: Comparing predicted values with the actual values can provide insights into the model's accuracy.
Step 10: Improving the Model (Optional):
If you want to improve the model's accuracy, here are a few steps you can try:
Use More Features: Add more features from the dataset to see if they improve the accuracy.
Apply Feature Scaling: Some algorithms perform better with scaled data.
Experiment with other models: Try models like Decision Trees or Random Forests for potentially better performance.
Conclusion
Congratulations! We’ve built our first machine learning model in Python. By following this guide, we’ve learned how to load a dataset, explore the data, train a model and evaluate its performance. Keep experimenting with different datasets and algorithms to deepen your understanding of machine learning.

Comments